
为什么同样的错误AI能犯一百遍?教你把每次纠偏都存下来!
一、全文速览图 大家用 AI 用久了,有没有一种诡异的感觉。
最近几个月一直在搭建个人的 AIOS。
我们都知道现在 Agent 有一个很大的痛点,不知道你现在的状态,也不知道你的目标,在企业里做项目一般有企业知识库解决这个问题。
但是对于个人又不一样,企业的都是和工作相关。涉及到和自己相关的怎么办呢?
你个人的信息、喜好。你的三年五年规划,甚至你的健康、财务情况等等。
这些信息 AI 知不知道,怎么消费?能不能影响到 AI 给你的下个决策或者方案。
一般的 Agent 就算有记忆,也只是粗暴地塞到一个小小的 md 里,或者零散扔在某个记忆文件夹,最后基本成了死数据,系统的应用难度非常大。
刚开始我迷恋各种 SKILL 和自动化。做下来才发现,问题往往在工具层之外:「从现状到理想」的闭环,好像并没有真的转起来。
最近让我的 AI 定期在网上学习项目,冲浪的时候。无意间看到了 PAI(Personal AI Infrastructure)这个项目,已经迭代到 V5 版本了,有 14.5K star。
和我的想法很相近,而且写的更完整,所以想推荐给大家,如果你也有同样的问题可以看看它是怎么处理的。
它的自我定位很直接,也非常嚣张:,直接写着:我们不做 AI 套壳,也不做 Prompt 脚手架,我们是人生操作系统(Life Operating System)

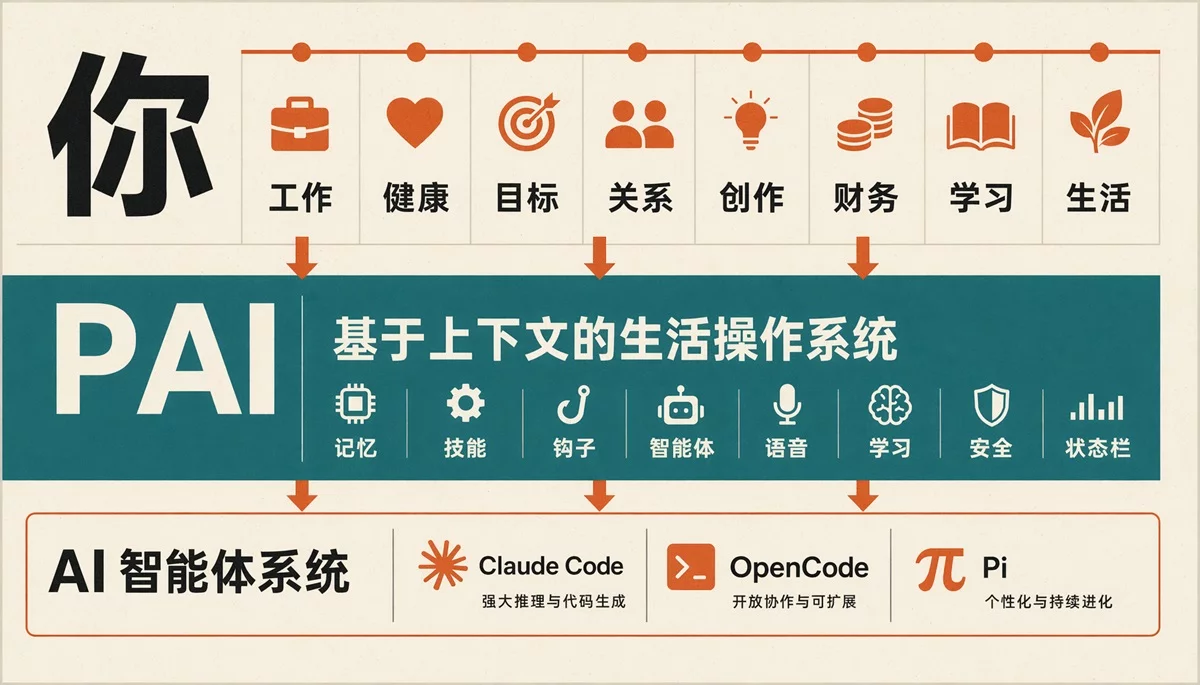
这张图是它设计的整体架构,大概分三层。
底层是 AI 引擎(Claude Code、OpenCode 等)
中间是 PAI OS(Memory、Skills、Hooks、Algorithm……)
顶层是你的生活域——工作、健康、目标、关系、财务。Context 在三层之间来回流。
多数产品只画中间一层,卷生卷死地比拼套壳,顶层完全是空的。
PAI 则是直接把顶层当成了真源: 没有真实的生活输入,AI 操作系统根本不知道自己在帮谁优化。
PAI 给自己的核心设计只命名了一条循环:
弄清现状 → 弄清理想 → 每次交互,选一步,缩小差距。
一句话就能说完。
但要让这句话真的转起来,还是挺复杂的。
以前看各种 Agent 框架,经常搬出多智能体协作的宏观流程图,看着极其震撼,真用起来又极其崩溃。
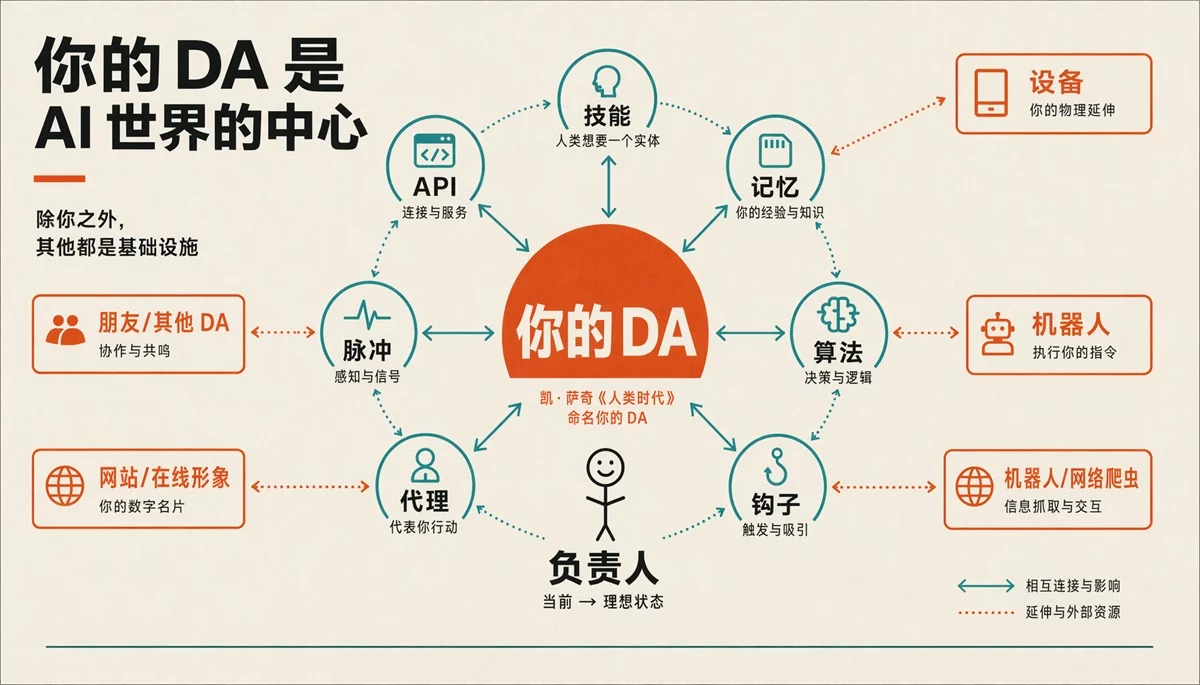
PAI 的思路非常清爽:
图里中间那个小人是我们 (Principal)。
我们只需要和我们的 DA(Digital Assistant)交流。官方还给他们设定了人设,叫 Kai、Sage,当然你也可以改成秦始皇或者刘华强。
DA 就是里面的主体,相当于是一个前台。
Skills、Memory、Algorithm、Hooks、Agents、Pulse、网页、设备…… 这些乱七八糟的,我们也不想懂的,全是 DA 够得着的后台基础设施,被DA调度。
他们和 DA 形成了一个个小闭环。
比如”DA 调一个 Skill、Skill 返回结果、DA 记进 Memory”——这就是一次小闭环。
DA 这些小闭环,一步步把你从现状推向理想。
它里面我总结了三大支柱,也就是它的特点,我们来一点一点看。
你可能搭建过复杂的 AI 系统。
它能写代码、查文献、做计划、帮你把各种念头整理成一份体面的方案。
做活可能挺溜,一个项目能读完差不多半个互联网。
但它还是不了解你。
那么你是谁?AI 怎么知道?
一般的 AI 都会放到单个的 MD 文件里,比如 user.md、agent.md、claude.md 五花八门。
PAI 则准备了一个专门装”你“的目录,叫 USER/。
官方对它的设计原则有一句话:
走进去应该像在读一个人的传记,不是翻文件柜。
里面是一组 Markdown 文件,每个管一块:
这些文件里面有各自的标签,比如 voice、mind、identity 来区分文件的类型

同时里面也内置了大量的源头,比如日程、邮箱等方便直接同步信息。
我们可以看到,里面的内容十分详细,从个人风格、观点这些常见的,到你的健康、财务、社交关系等等都被囊括。
这些信息自然不是一个 User.md 能比的。
如果你要写东西,它知道你的声音、你平时爱引用哪类书、爱听的音乐、爱看的电影,把这些东西填入到你的内容中,这些才是构成”活人感“的关键。
如果你要调整作息,它知道你的生活节奏、健康、精力、状态,自然能给出更好的方案。
这些文件通过路由、渐进式的方式,被 AI 按需读取。
有了这些,DA 给你的建议才不是悬空的。
你想去哪——TELOS 与理想态
知道你是谁,还不够。它还需要知道你往哪走。
PAI 用 TELOS 来装这层。TELOS 是希腊文,目的、终点的意思。在 PAI 里,它是你的方向层——你在解决什么问题、使命是什么、今年要实现什么、打算怎么打,全部落成文字,串成一条链:
问题 → 使命 → 目标 → 策略 → 项目
也就是说干任何一件具体事前,都要往上追溯到我们的上层目标,根据目标来推导我们下一步的决策。

不是一个文件,也是一组文件,各管一块。
毕竟方向的不同部分变化频率不一样——使命可能几年不动,今年重点项目可能一个月换三次,新的卡点也可能随时冒出来,单个文件不方便管理。
PAI 用一个 HOOK 自动把这些源文件压成一份短摘要——PRINCIPAL_TELOS.md。
每次对话开始自动加载 ,同时你如果改了源文件,摘要也会由 HOOK 自动重建。
此刻你在哪
方向有了,其实还差一件事:你现在在哪?
PAI 专门留了 CURRENT_STATE。
用来记录当下各维度的真实情况,健康、财务、工作、关系,分开记录。
有了这层,DA 才能做真正的理想和现实的差距分析,不是给你一个听起来不错但完全不落地的方案。
比如你现在现金流吃紧,DA 就不该跟你聊扩张;
你最近精力不足,排日程就应该给你留缓冲,饮食安排上肾宝,而不是继续逼你一把,把你燃尽榨干。
大多数 AI 给建议的时候,完全不知道你处于哪个状态,所以经常是这种效果——听着好像没毛病,但跟你实际处境又完全对不上。
前面我们讲明白了,闭环里面的现状和理想, 那执行可以直接交给 AI 吗?
显然也不行。
我经常碰到让 AI 干一件事,它语气非常笃定地说干完了,输出洋洋洒洒,有理有据,如果它是人,我都能想象到它的表情。
定睛一看,内容全错了,你应该能想象到我的表情。
这时候不用怀疑,AI 大概率不是故意骗你。
核心原因是它根本不知道「完」在哪里,你也没告诉它。
“做完了”这件事从来没被认真定义过。
PAI 的答案是:动手前先把「完」写成合同,收工前对着合同逐条验。
ISA:给「完成」立一份账。
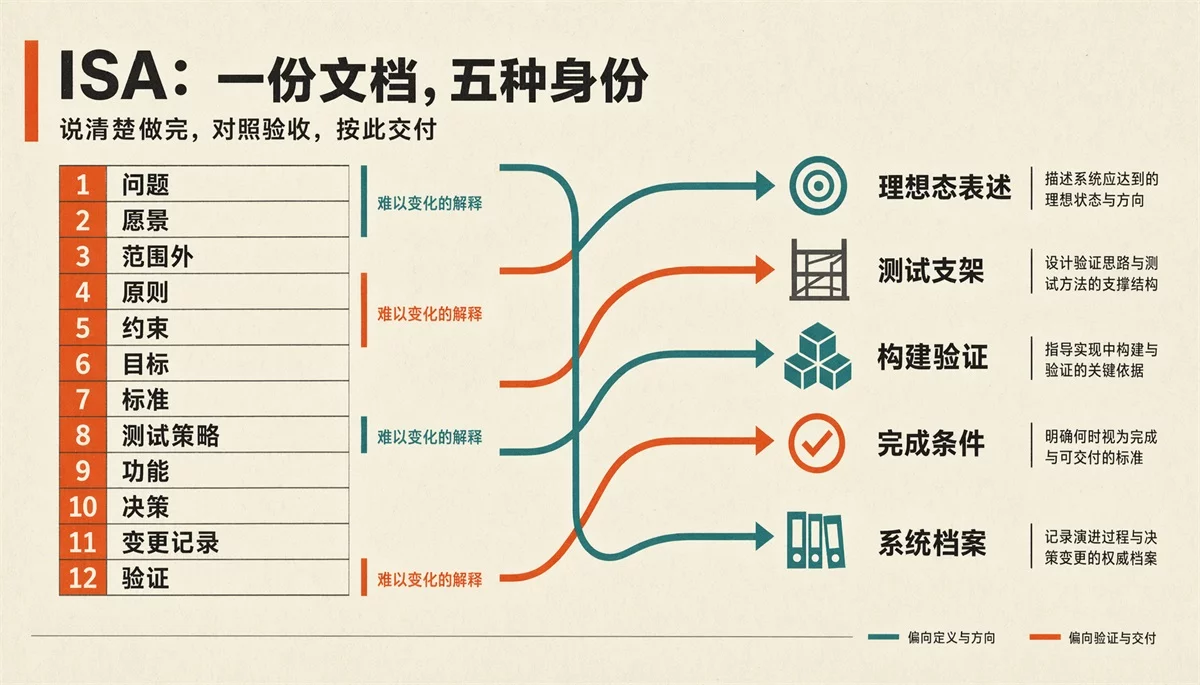
PAI 用 ISA(Ideal State Artifact)来装这份「完的合同」。
我们要把一件事做完,最少需要五件东西:需求文档、验收标准、测试用例、决策记录、系统档案。传统情况下可能是 5 人的分工,我们也习惯了五件东西放五个地方。
但是改一处其他四处可能都不知道,就像需求改了,产品不通知我一样。
我还跟个二傻子一样看着旧需求继续做。
PAI 认为这些都是鸿沟,人也一样,AI 也一样。
所以 ISA 把这些压成了一份文件,它需要同时承担这五种身份:
- 需求描述:这件事要解决什么问题、完成的样子是什么
- 测试用例:根据 ISC 测试
- 验收合同:ISC 全过 = 验收通过,纯机械判断,没有「差不多」
- 完成条件:记录完整的标准
- 系统记录:任务的完整轨迹,下次参考
这样改一处,五个视角会同步跟着变。
ISC:把「感觉差不多」变成勾选项
ISC(Ideal State Condition)是 ISA 里的验收条目,每一条对应一个可以跑的最小事实,或者说一个标准。
不是像:功能完整、读起来顺畅,这种抽象的没什么用的描述。
而是更具体的落地的,比如:
- 目标文件存在,路径能打开
- 终端没有报错
- 原来的数据没有被覆盖
ISC 有三种类型:

每条只会有两个结果:过,或没过。全部过了,AI 才允许说做完。
Algorithm:七步把 ISA 走完
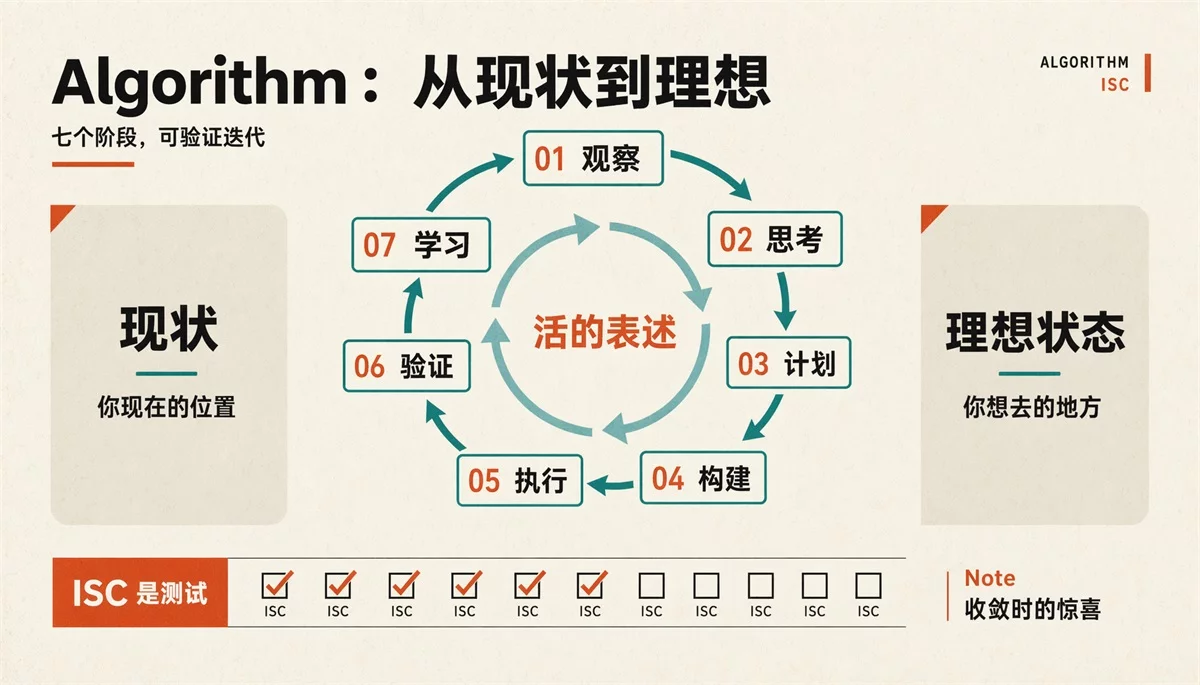
ISA 定义了终点,ISC 是检查点。
还是差点意思,并不是我定义了和标准,AI 就听话了。
AI 的执行路径也很重要,Algorithm 是走这段路的过程。
PAI 定义了完成这个步骤的流程,一共七个阶段,形成了一个完整的闭环:
OBSERVE → THINK → PLAN → BUILD → EXECUTE → VERIFY → LEARN
说人话就是:观察 → 思考→ 拆任务 → 动手 → 跑 ISC → 逐条验 → 写回档案
第一步 OBSERVE 就建出 ISA,把这件事的理想态和验收标准全写进去。
接下来每一步都在读取 ISA、并且进行迭代,不断的写入新的状态信息
比如发现边界变了记一条,ISC 跑过了就打个勾。
比如这把如果踩了坑写进 Changelog,避免下轮再犯。
一轮任务结束时你拿到的 ISA,远远不止刚开始的初稿,是被七步磨出来的、有来源可追溯的完整档案。
下次遇到同类任务,也不是从零开始,是从这份档案开始。
流程里还有几十个 Hooks 在关键节点卡着,完善这段闭环:
比如 Stop 的时候必须有真实产物,修了 bug 要先复现,产物能打开才算完成。
由此执行的路径也达成了闭环。
支柱一让 DA 知道你是谁、要去哪、此刻在哪;
支柱二让「完」可以验。
但干完了如果全散在聊天记录里——进行中的活、上次推过的假设、我们和AI的激情对喷等等,没地方消费,下次开聊就还得从头交代。
主环这么转了一圈,什么都没留给下一圈,这显然不行。
这就是第三层要解决的:记忆要能复利,不能只是归档。
三个桶,分别存三种东西
PAI 把记忆拆成三类
- WORK——还没完的事。比如:任务、进度、进行中的 ISA。下次开聊能直接读取,接着干,不用重新讲背景。
- KNOWLEDGE——稳定的事实和记录。某个人是干什么的、某家公司的信息、某个项目结论。能够随时查得到,辅助我们决策。
- LEARNING——学到了什么。你纠正过的地方、哪次交付不满意、AI犯的那些蠢,这些都是有价值的,需要经过提炼之后进桶,不能消失在对话尾巴里。
那么记忆是怎么自动积累的?
里面设计了不少流程,我简单说三种。
① 聊天的时候,通过 HOOK 给你的情绪打分。
比如你说“继续”——那就是 5 分,正常。
说”我 C“—— 那就是 1 分。
说”牛逼“—— 那就是 8 分。
分数低到一定程度,它会把整段对话、你的情绪、出错在哪,全部打包存档。
就像行车记录仪,碰到事故自动保存现场。
② 对话结束,有 7 个 HOOK 在跑
比如:
他们会把这次任务的结果写进学习记录
记下这次任务改了什么文件
给系统做健康检查。
还有一个专门记录「关系笔记」的,它会写下今天你专注在什么事上、你表达过什么偏好、它自己这次做得怎么样,每条还附一个置信度百分比。
日积月累,就变成了一个和 AI 的磨合笔记
③ 每过一段时间,都会去翻你的旧对话
它也设置有专门的定时任务,类似 openclaw 的做梦,去扫描过去几周的对话记录,把里面零散的纠正、判断、偏好挖出来,归入对应的记忆目录
所以每次对话,它的起点总会比上次高一点,这就是记忆的复利。
大概讲这么多吧,里面的内容其实很多,你如果在搭自己的个人 AI OS,PAI 的思路有很大的参考价值,虽然不必全部照搬,但这几个问题是躲不开的:
系统知不知道你是谁、要去哪、此刻在哪?
什么叫做完?
上次的事下次还在不在?
希望对大家有所帮助。
Github地址
https://github.com/danielmiessler/LifeOS
来源:https://www.uisdc.com/aios



