上篇博客写了亚马逊产品页视频在线下载小工具:亚马逊Amazon页面产品视频在线下载方法
这里分享下底层的代码逻辑,其实用python爬虫代码(网上有m3u8视频抓取代码)即可实现,一起来看看吧。

打开视频页面:
https://www.amazon.com/vdp/06ef28070ddf4d40b6460b4e10918191?ref=dp_vse_rvc_0
使用浏览器抓包发现,这个视频是m3u8格式的。m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8。

找到Url:
https://m.media-amazon.com/images/S/vse-vms-transcoding-artifact-us-east-1-prod/367b6f18-ec99-49d0-b2a5-46eb032fd886/default.jobtemplate.hls.m3u8
打开内容如下:
#EXTM3U #EXT-X-VERSION:3 #EXT-X-INDEPENDENT-SEGMENTS #EXT-X-STREAM-INF:BANDWIDTH=1070623,AVERAGE-BANDWIDTH=893710,CODECS="avc1.4d401f,mp4a.40.5",RESOLUTION=854x480,FRAME-RATE=29.970 default.jobtemplate.hls480.m3u8 #EXT-X-STREAM-INF:BANDWIDTH=1838472,AVERAGE-BANDWIDTH=1496383,CODECS="avc1.4d401f,mp4a.40.5",RESOLUTION=1280x720,FRAME-RATE=29.970 default.jobtemplate.hls720.m3u8 #EXT-X-STREAM-INF:BANDWIDTH=3698764,AVERAGE-BANDWIDTH=2984822,CODECS="avc1.640028,mp4a.40.2",RESOLUTION=1920x1080,FRAME-RATE=29.970 default.jobtemplate.hls1080.m3u8 #EXT-X-STREAM-INF:BANDWIDTH=702464,AVERAGE-BANDWIDTH=587543,CODECS="avc1.77.30,mp4a.40.5",RESOLUTION=640x360,FRAME-RATE=29.970 default.jobtemplate.hls360.m3u8
可以看到它包含几种清晰度的视频:360, 480, 720, 1080. 我们选择 1080版本的m3u8文件, 把上面的url替换成1080的链接:
https://m.media-amazon.com/images/S/vse-vms-transcoding-artifact-us-east-1-prod/367b6f18-ec99-49d0-b2a5-46eb032fd886/default.jobtemplate.hls.m3u8
下载,编辑器打开如下:
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:7 #EXT-X-MEDIA-SEQUENCE:1 #EXT-X-PLAYLIST-TYPE:VOD #EXTINF:6, default.jobtemplate.hls1080_00001.ts #EXTINF:6, default.jobtemplate.hls1080_00002.ts #EXTINF:6, default.jobtemplate.hls1080_00003.ts #EXTINF:6, default.jobtemplate.hls1080_00004.ts #EXTINF:6, default.jobtemplate.hls1080_00005.ts #EXTINF:6, default.jobtemplate.hls1080_00006.ts #EXTINF:6, default.jobtemplate.hls1080_00007.ts #EXTINF:6, default.jobtemplate.hls1080_00008.ts #EXTINF:6, default.jobtemplate.hls1080_00009.ts #EXTINF:6, default.jobtemplate.hls1080_00010.ts #EXTINF:6, default.jobtemplate.hls1080_00011.ts #EXTINF:6, default.jobtemplate.hls1080_00012.ts #EXTINF:6, default.jobtemplate.hls1080_00013.ts #EXTINF:5, default.jobtemplate.hls1080_00014.ts #EXT-X-ENDLIST
m3u8 是一种又 .ts 音视频片段拼凑而成的文件,当浏览器加载 .m3u8 文件时,我们可以看到后台 ajax 是分一段一段加载的, 也就是看到哪加载到哪。
其实关于m3u8格式的视频下载,网上已经有很多教程了,也有人做出了小工具,可以直接拿过来用,也是非常卷了!这里使用【PY-GZKY】写的小教程来演示。
【PY-GZKY】的小教程链接:https://github.com/PY-GZKY/python-automation-docs/blob/master/docs/%E7%88%AC%E8%99%AB/m3u8%E9%9F%B3%E8%A7%86%E9%A2%91%E6%8B%BC%E6%8E%A5.md
下载m3u8视频的代码可以借鉴修改一下来使用,核心代码如下:
import time
import os
import requests
import re
# 查找m3u8文件中的ts路径列表
def get_ts_urls(url):
# 请求视频页面,获取m3u8网址
r = requests.get(url)
data = r.text
# 正则匹配出m3u8网址
m3u8_urls = re.findall('"videoURL":"(.*?)"', data)
m3u8_url = m3u8_urls[0]
# 替换为1080
m3u8_url = m3u8_url.replace('hls.m3u8', 'hls1080.m3u8')
# 获取m3u8文件内容
meu8_data = requests.get(m3u8_url).text
# 查找ts文件的行, 并且补全成完整url链接
url_base = m3u8_url.replace('default.jobtemplate.hls1080.m3u8', '')
urls = []
lines = meu8_data.split("\n")
for line in lines:
if line.endswith(".ts"):
# print(line)
urls.append(url_base + line)
return urls
def download(ts_urls, download_path):
if not os.path.exists(download_path):
os.makedirs(download_path)
for i in range(len(ts_urls)):
ts_url = ts_urls[i]
file_name = ts_url.split("/")[-1]
print("开始下载 %s" % file_name)
try:
response = requests.get(ts_url, stream=True)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "/{0}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
time.sleep(.56)
def file_walker(path):
file_list = os.listdir(path)
# file_list.sort()
file_list.sort(key=lambda x: int(x[:-3]))
file_list_ = []
for fn in file_list:
# print(fn)
p = str("tsfiles" + '/' + fn)
file_list_.append(p)
print(file_list_)
return file_list_
def combine(ts_path, file_name):
file_list = file_walker(ts_path)
file_path = file_name + '.mp4'
with open(file_path, 'wb+') as fw:
for i in range(len(file_list)):
fw.write(open(file_list[i], 'rb').read())
if __name__ == '__main__':
url = 'https://www.amazon.com/vdp/06ef28070ddf4d40b6460b4e10918191?ref=dp_vse_rvc_0'
urls = get_ts_urls(url)
download(urls, "tsfiles")
combine("tsfiles", "toys")
依次下载的ts文件,都是一个个几秒的小视频文件
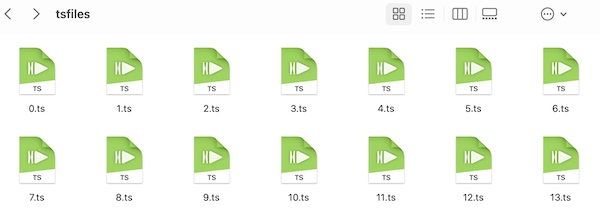
之后使用combine()函数对这些ts文件进行合并,得到一个mp4文件,如下图所示:

转载请注明:拈花古佛 » 用Python获取亚马逊商品页面的m3u8格式视频